NoSQL Database - Simplified
We have heard about the term NoSQL so many times. It's the most widely used word nowadays when it comes to selecting databases.

I will not waste your time by saying all the things like why we should use or compare it with relational databases. Instead, I will focus on deep thought about why even someone created a Non-SQL database in the first place!
We already have SQL databases out there and it's working pretty fine!
Why would I think to change it?
I will present two things here:
- The reason behind invention of NoSql.
- Considerations while working with Nosql.
Why?
“Asking the right question is the first step when we are looking for a solution.”
When we are working with relational databases, we have the option to scale the database as per our requirement.
Scalability becomes a bigger issue here.I am using 4GB machine with 2 CPUs. Then, I'll buy 8 GB machine. Simple, right?
If we consider moving 2 decades back, we had a limited amount of data in GB or max in a few TBs. As we
all know, with the increase in internet users, the data size increased drastically. Nowadays, a company
processing 100 TB of data is also a new normal.
So if we want to scale-out a relational database, then we need more CPU and more memory. But there
is a hard limit when it comes to capacity increase in hardware. That's when the most important issue
arises.
When we have a guest in our house, should we buy another room OR sell our house and buy another bigger house!
What if I can attach another 4 GB machine instead of buying 8 GB!
Hidden Space consumption
Let's say, I have a database to handle social media operations. I'm storing user details like Name, address, email, phone number, etc. in my relational database. Now, all of the users will not give all the details. (I only fill required fields in the form 😉)
So in that case, the empty field will be marked as Null. Now, this null is also consuming space of 2 bytes. It depends on the schema of the table. It seems too low in first thought, right? Why would I care for 2 bytes!
Think of the 100 million registered users on social media sites.
i.e. 100 million x 2 bytes of wastage!
It’s a huge amount of space wastage that we can't ignore!
"I'm paying 100s of dollars for storing Null values, seriously!"
Lastly,
Another important thing is, SQL is not meant for storing documents, key-value
stores, or graph databases. We even use nested document structure nowadays. Think of how many different
tables we have to create in case
of nested key-value pairs in relational databases. That's why it's not meant for a different purpose.
Considerations while designing
I am planning to use a NoSQL database. What should I keep in mind before I start designing?
I will take AWS DynamoDB in mind while explaining things. You can pick other available DBs as per your need.
In case of relational schema, we divide our tables while performing normalization. On the other hand, we
should use minimum number of different tables in NoSQL case. If possible use only one table.
More table, more cost!
Because, we don’t have JOINS in this type. Also, we are paying per request bases. We might end up
paying more if we use multiple tables.
I will take a simple example. Let's say, we are storing data on Social Media. We have 2 tables like User Details and Address. And your use cases include:
- List user details with the address for the given name.
- List users that belong to a given city.

We might create these 2 tables in SQL and perform Join operations. In case of DynamoDB, we should use only one table. You can use Global secondary index City to perform 2nd use case.
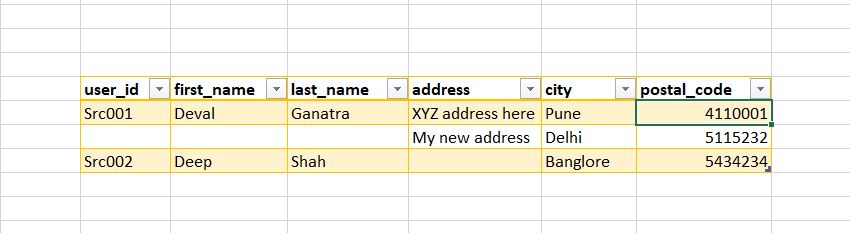
I can easily query, who's living in Pune with my GSI and it will show up both the user's details.
I will show you another interesting way! Consider following use cases:
- Get delivery details of given userid
- Get personal details of given userid
- Get shop details and its items.
- Get Users that by city (with use of GSI).
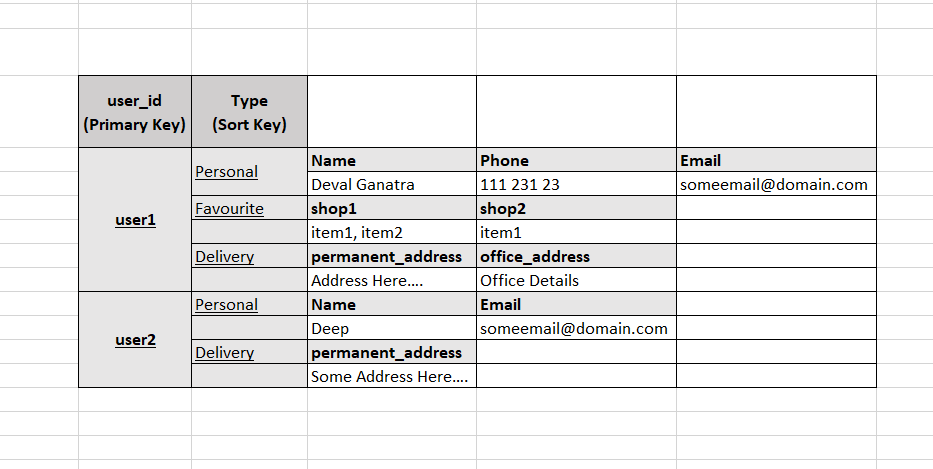
Use PrimaryKey user_id and SortKey that startswith Delivery . That's it! We solved first use case.
We can also handle one to many relationships in this one table only. Try it out yourself. DynamoDB is dynamic enough to achieve that easily.
Deleting batch entries are costly!
Suppose you have a use case where you need to delete multiple entries on daily/weekly basis.
So what? I will add/remove the entries from table.
AWS charges us on per request (RCU and WCU) basis. It means the more we will send read/write API calls, the more we will be charged. Now, if you are deleting multiple entries then it will cost us more.
Instead, the better way is to delete a table instead!
Sounds crazy, but its good option. Create temporary tables for that daily/weekly entries and remove when you don't need them.
Bonus Tip:
Last but not least, we need to hire database admins in case of large applications! Not for No-SQLs. Save
cost by using it!
Just kidding.
Did you like what you read? Recommend this post to others!
Want to share something? I would Love to hear from you!